
Graph Databases vs Relational Databases: What and why?
In this article, we will be looking at the Graph Database and Relational Database. This will be a basic introduction to both databases. We will talk about the pros and cons of course and where should you use which database.

Mar 28, 2023
Database, It is an organized collection of structured information, or data, typically stored electronically in a computer system. In the modern world, where technology is evolving day by day. You might have heard of Relational and Graph Databases, as they are very common. If you never heard of any of them then fasten your belt cause you are about to be introduced to both the database.
In this article, we will be looking at the Graph Database and Relational Database. This will be a basic introduction to both databases. We will talk about the pros and cons of course and where should you use which database. Let's dive right in.
Graph Database
A graph database is a type of database that stores data in terms of nodes and edges. The data is stored in a very flexible way without following a pre-defined model. This graph forms a relationship between two nodes this relationship can be either directed or undirected. These databases are designed to handle the complex relationship between data/nodes.
Nodes are used to store the data. Each node contains a set of properties that give information about the node itself.
An Edge stores the relationship between two nodes or entities. An edge always has a starting and ending node.
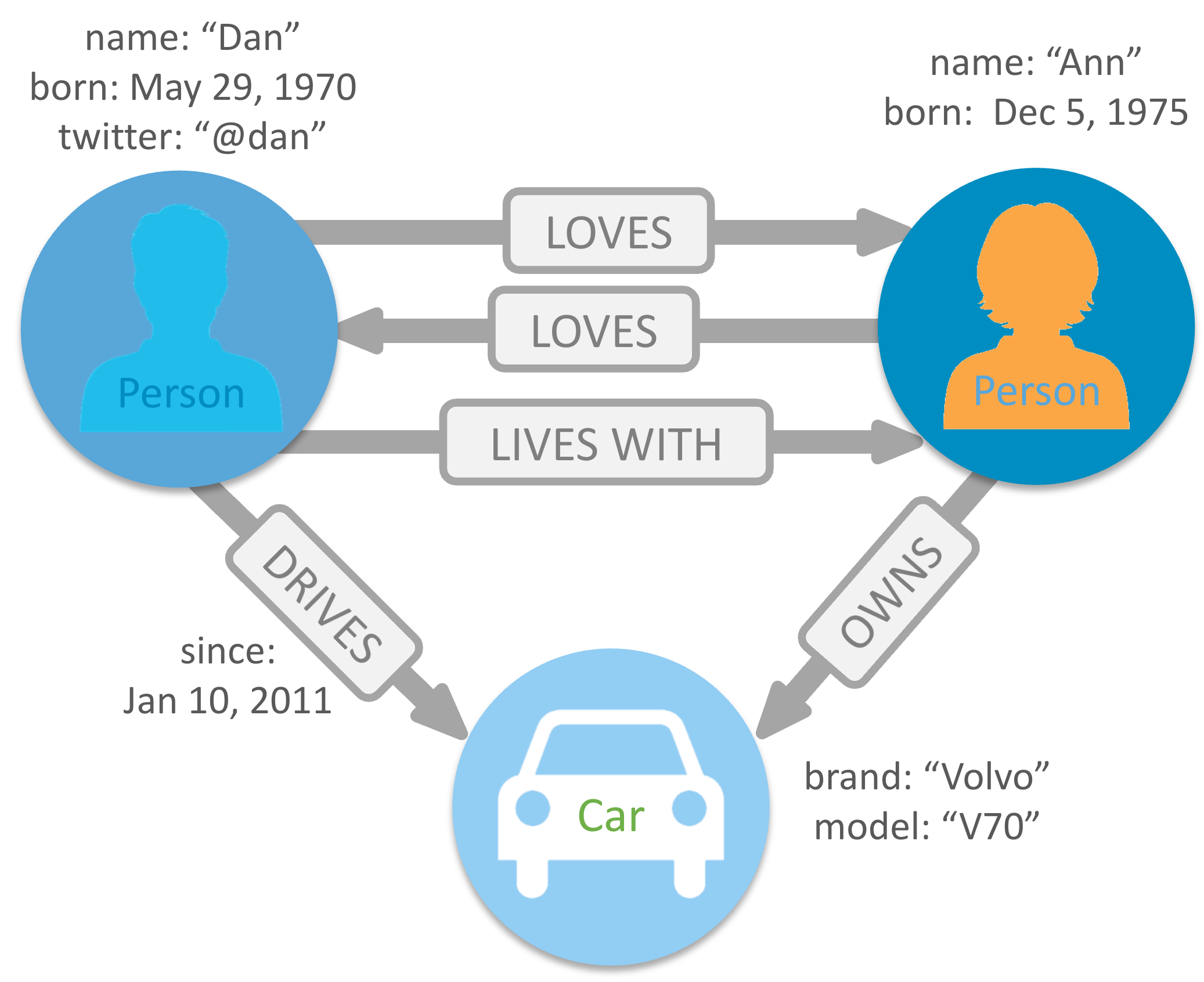
How do Graph Databases work?
Unlike traditional relational databases, which rely on tables and columns, graph databases use a schema-less structure. This means that there are no predefined tables or columns, and data can be stored in a flexible, scalable, and efficient manner.
Graph databases use various types of data models, including property graphs and RDF (Resource Description Framework) graphs. In property graphs, each node and edge can have multiple properties, which are key-value pairs that describe the attributes of the node or edge. In RDF graphs, nodes and edges are represented as URIs (Uniform Resource Identifiers), and relationships between entities are represented using triplets (subject, predicate, object).
Graph databases typically use a query language, such as Cypher or Gremlin, to traverse the graph, query data, and update data. These query languages are designed to be user-friendly, making it easy for engineers to work with graph databases.
When to Use Graph Databases?
Graph databases are used when it involves complex data. They are particularly useful for applications requiring the ability to model and query relationships between entities, such as in social networks, recommendation engines, and fraud detection systems.
Social Networks
As we know Social Networks are very highly complex and highly connected. And they follow very complex data structures. They follow the relationship between users' posts, comments and other entities. Graph databases allow users to easily traverse the graph and discover between entities.
Here is an example of how a graph database can be used in a social network:
from py2neo import Graph, Node
# set up graph connection
graph = Graph()
# create user node with attributes
user = Node("User", name="John Doe", age=25, location="New York", interests=["programming", "video games"])
# add user node to graph
graph.create(user)from py2neo import Graph, Node
# set up graph connection
graph = Graph()
# create user node with attributes
user = Node("User", name="John Doe", age=25, location="New York", interests=["programming", "video games"])
# add user node to graph
graph.create(user)The above code creates a user node with attributes such as name, age, location, and interests, and adds it to a graph database.
Recommendation Engines
Recommendation engines are machine learning algorithms used to suggest items to users based on their previous actions, preferences, and behaviors. They are commonly used in e-commerce websites, streaming platforms, and social media websites to provide personalized recommendations to users.
Graph databases can be used in recommendation engines to represent and process data more efficiently and effectively. Graph databases are designed to store and query relationships between entities, which is a fundamental aspect of recommendation engines. Here's an example of how a graph database can be used in a recommendation engine:
Let's say we want to build a movie recommendation engine. We can represent movies and users as nodes in a graph, and use edges to represent relationships such as movie ratings and user preferences.
Each movie node can have attributes such as title, genre, director, and actors. Each user node can have attributes such as age, gender, and location. The edges between the nodes can represent different types of relationships. For example, a "watched" edge can connect a user node to a movie node, with a rating attribute representing the user's rating of the movie.
By using a graph database, we can easily query the graph to make recommendations for a specific user. For example, we can find movies that similar users have rated highly, or find movies that are related to ones that the user has rated highly.
Here's an example of how to add a movie node to a graph database using the Python package py2neo:
from py2neo import Graph, Node
# set up graph connection
graph = Graph()
# create movie node with attributes
movie = Node("Movie", title="The Matrix", genre="Science Fiction", director="Lana Wachowski", actors=["Keanu Reeves", "Carrie-Anne Moss"])
# add movie node to graph
graph.create(movie)from py2neo import Graph, Node
# set up graph connection
graph = Graph()
# create movie node with attributes
movie = Node("Movie", title="The Matrix", genre="Science Fiction", director="Lana Wachowski", actors=["Keanu Reeves", "Carrie-Anne Moss"])
# add movie node to graph
graph.create(movie)The above code creates a movie node with attributes such as title, genre, director, and actors, and adds it to a graph database using the py2neo package. You can add more nodes to the same graph.
Fraud Detection Systems
FDS requires the ability to identify suspicious behavior through various types of patterns. Graph databases are very useful in fraud detection as they can analyze the relationship and identify that may indicate a scam.
Here's an example in Cypher that retrieves all transactions involving the same credit card from different merchants:
MATCH (c:CreditCard)-[:USED_FOR]->(t:Transaction)-[:AT_MERCHANT]->(m:Merchant)
WITH c, m, COUNT(t) AS tx_count
WHERE tx_count > 1
RETURN c.number, m.name, tx_countMATCH (c:CreditCard)-[:USED_FOR]->(t:Transaction)-[:AT_MERCHANT]->(m:Merchant)
WITH c, m, COUNT(t) AS tx_count
WHERE tx_count > 1
RETURN c.number, m.name, tx_countWhat this query does is it matches all the credit cards that are used for transactions at different merchants, and returns the credit card number, merchant name, and the number of transactions involving that credit card at the merchant. This could help to identify a scam.
How to use Graph Databases?
Now you know what are graph databases and how they work and when you can use them. Now the question arises "Ok, That's cool, But how can I use it?"

There are a few steps that you need to follow to use a Graph database-
1. Choose a graph database software
First, you need to choose a specific graph database platform to work with, such as Neo4j, OrientDB, JanusGraph, Arangodb or Amazon Neptune. Once you have selected a platform, you can then start working with graph data using the platform's query language.
2. Plan your graph model
Once you have chosen the database software, define the entities and the relationships between them. You can use paper and pen or a diagramming tool to create a visual representation of the graph model.
3. Create a graph database
After finalizing the graph model, create a new database instance in your graph database software. Depending on the software, you can either use the command line or a GUI to create a new database instance.
4. Define the schema
Before adding nodes and edges to the graph database, define the schema. The schema defines the entity and relationship types, the properties, and their data types. Most graph database software supports dynamic schema updates. (I know I said "It is a schema-less structure" but it's better to define an overview structure)
5. Add nodes and edges
Nodes represent the entities in the graph database, and edges represent the relationships between entities. You can add nodes and edges using the software's specific language such as Cypher
CREATE (user:User {name: 'Jatin'})
CREATE (article:Article {title: 'Graph Databases vs. Relational Databases'})
CREATE (user)-[:WROTE]->(article)CREATE (user:User {name: 'Jatin'})
CREATE (article:Article {title: 'Graph Databases vs. Relational Databases'})
CREATE (user)-[:WROTE]->(article)The above code creates two nodes, one with the label "User" and one with the label "Article", and then creates a relationship between the two nodes using the WROTE relationship type.
6. Querying Data
To query data, you can use the MATCH clause in Cypher. For example, to find all articles that Jatin has written, you could use the following code:
MATCH (user:User {name: 'Jatin'})-[:WROTE]->(article:Article)
RETURN article.titleMATCH (user:User {name: 'Jatin'})-[:WROTE]->(article:Article)
RETURN article.title7. Updating Data
To update data, you can use the SET clause in Cypher. For example, to update the title of an article with the ID 47 to "Graph Databases", you could use the following code:
MATCH (article:Article {id: 47})
SET article.title = 'Graph Databases'MATCH (article:Article {id: 47})
SET article.title = 'Graph Databases'8. Deleting Data
To delete data, you can use the DELETE clause in Cypher. For example, to delete an article node with the id 47 along with any relationships connected to the node, you could use the following code:
MATCH (article:Article {id: 47})
DETACH DELETE articleMATCH (article:Article {id: 47})
DETACH DELETE articleThis code starts by matching the article node and then detaches any relationships connected to the node before deleting the node itself.
Pros of Graph databases
- They are very flexible to handle complex data and relations.
- They use graph traversal to navigate through a large amount of interconnected data.
- They can also scale horizontally, which means adding more machines to handle increasing amounts of data.
- Graph databases can perform real-time updates on big or small data while supporting queries at the same time.
Cons of Graph databases
- They may not be as efficient for structured data that fits neatly into tables and rows.
- They are more complex and may require more knowledge than relational databases.
Relational Databases
A relational database is a collection of information that organizes data in predefined relationships where data is stored in one or more tables (or "relations") of columns and rows. The tables are related to each other through a set of keys called foreign keys, which define the relationships between the data.
A row represents the record in the table. and have a unique key.
The columns of the table hold attributes of the data, and each record usually has a value for each attribute.

When to use Relational Databases?
Relational databases are ideal for situations where data needs to be stored in an organized and controlled way and accessed via complex queries. However, there are cases where other database solutions may be more suitable:
Store structured data
When you have a large amount of data that needs to be organized in a logical order, a relational database is a good choice. You can define tables with a clear schema, and enforce relationships between the data.
Ensure data integrity
Relational databases have built-in mechanisms to ensure the integrity of data. By defining relationships between tables, you can enforce constraints that keep your data clean and consistent.
Perform complex queries
Structured Query Language (SQL) provides a powerful language to work with data in relational databases. With SQL, you can retrieve data, filter it, sort it, and aggregate it in a variety of ways.
Scale horizontally
Relational databases can be scaled horizontally, meaning you can distribute tables across multiple servers. This can be particularly useful when dealing with very large datasets that cannot fit on a single server.
How do Relational Databases work?
As I already mentioned that they work in the form of rows and columns which forms a table. This structured format makes it easy to search and retrieve specific data and allows more complex data queries to be performed.
Let's say we have an e-commerce website that sells products. We want to store information about the products, the customers, and the orders they place. Here's how we could create a relational database to store this information:
- Tables: We'll create three tables -
products,customers, andorders. Each table will have its own unique name and contain a set of rows (records) and columns (fields). - Primary Key: Each table needs a primary key to uniquely identify each row in the table. For example, in the
productstable, we haveproduct_id. In thecustomerstable, we havecustomer_idAnd in theorderstable, we haveorder_idas the primary key. - Foreign Key: To establish relationships between tables, relational databases use foreign keys. A foreign key is a column in one table that matches the primary key of another table, creating a relationship between the two tables. For example, in the
orderstable, we could have a column calledcustomer_idrefers to thecustomer_idcolumn in thecustomerstable. This establishes a one-to-many relationship between thecustomersand "orders" tables, where each customer can have many orders. - SQL: We can use SQL to create and manage the database. Here's an example SQL statement to create the "products" table:
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR(255),
price DECIMAL(10,2)
);CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR(255),
price DECIMAL(10,2)
);This creates a table called "products" with three columns - product_id, product_name, and price. The product_id column is the primary key.
How to use Relational Databases?
To use relational databases, you need to follow these steps:
1. Create a database
First, you need to create a new database to store your tables and data. This can usually be done using a database management tool like MySQL, PostgreSQL, or Microsoft SQL Server. You'll need to choose a name for your database and configure any necessary settings.
2. Design your schema
This is the major step cause as relational database follows the schema approach so we need to create one. So, you need to design the schema for your database. This involves creating tables and specifying the columns and data types for each table. You'll also need to define relationships between tables using primary and foreign keys.
3. Populate your database
After your schema is designed, you can start adding data to your tables. This can be done using SQL commands to insert data directly into the database, or you can use a graphical interface to add data manually.
4. Query your database
After your data is added, you can start running queries against your database to retrieve specific data or perform calculations. This can be done using SQL commands or a query builder tool.
Let's take our old example of products and perform some queries there on the products table using SQL:
Creating a new record
INSERT INTO products (product_id, product_name, price) VALUES (1, 'Product 1', 9.99);INSERT INTO products (product_id, product_name, price) VALUES (1, 'Product 1', 9.99);This SQL statement inserts a new record into the products table with values for the product_id, product_name, and price columns.
Reading data
SELECT * FROM products;SELECT * FROM products;This SQL statement retrieves all records from the products table. We can also specify a condition to retrieve specific records. For example, to retrieve products with a price less than 10:
SELECT * FROM products WHERE price < 10;SELECT * FROM products WHERE price < 10;Updating data
UPDATE products SET price = 8.99 WHERE product_id = 1;UPDATE products SET price = 8.99 WHERE product_id = 1;This SQL statement updates the "price" column for the record with product_id 1 to 8.99.
Deleting data
DELETE FROM products WHERE product_id = 1;DELETE FROM products WHERE product_id = 1;This SQL statement deletes the record with "product_id" 1 from the "products" table.
Now, before you go like

Let me show you a few complex queries that we can do in the example that we took earlier:
Scenario 1:
We want to find the top 5 customers who have spent the most money on orders and show their order details. Here is the query for that:
SELECT
customers.customer_name,
orders.order_date,
products.product_name,
order_items.quantity,
products.price * order_items.quantity AS order_total
FROM customers
JOIN orders ON customers.customer_id = orders.customer_id
JOIN order_items ON orders.order_id = order_items.order_id
JOIN products ON order_items.product_id = products.product_id
GROUP BY customers.customer_id
ORDER BY SUM(products.price * order_items.quantity) DESC
LIMIT 5;SELECT
customers.customer_name,
orders.order_date,
products.product_name,
order_items.quantity,
products.price * order_items.quantity AS order_total
FROM customers
JOIN orders ON customers.customer_id = orders.customer_id
JOIN order_items ON orders.order_id = order_items.order_id
JOIN products ON order_items.product_id = products.product_id
GROUP BY customers.customer_id
ORDER BY SUM(products.price * order_items.quantity) DESC
LIMIT 5;Scenario 2:
Find all orders placed in the past month, and show the customer name, email address, and order details.
SELECT
customers.customer_name,
customers.email,
orders.order_id,
orders.order_date,
products.product_name,
order_items.quantity,
products.price * order_items.quantity AS order_total
FROM customers
JOIN orders ON customers.customer_id = orders.customer_id
JOIN order_items ON orders.order_id = order_items.order_id
JOIN products ON order_items.product_id = products.product_id
WHERE orders.order_date >= DATEADD(month, -1, GETDATE())
ORDER BY orders.order_date DESC;SELECT
customers.customer_name,
customers.email,
orders.order_id,
orders.order_date,
products.product_name,
order_items.quantity,
products.price * order_items.quantity AS order_total
FROM customers
JOIN orders ON customers.customer_id = orders.customer_id
JOIN order_items ON orders.order_id = order_items.order_id
JOIN products ON order_items.product_id = products.product_id
WHERE orders.order_date >= DATEADD(month, -1, GETDATE())
ORDER BY orders.order_date DESC;Pros of Relational databases
- Relational databases are well understood and have been in use for decades, so there is a large pool of expertise available.
- They are highly structured and allow for efficient querying of data using SQL.
- Relational databases can be scaled vertically, which means adding more resources to a single machine to increase performance.
- Users can easily access/retrieve their required information within seconds without indulging in the complexity of the database
Cons of Relational databases
- Maintaining large amounts of data can become difficult.
- They are not well suited to handling data with complex relationships or graph-like structures.
- A relational database is comprised of rows and columns, which requires a lot of physical memory.
Wrapping up
In this article, I've explained the graph and relational databases along with their pros and cons. In the end, I would say both graph databases and relational databases have different purposes and have their own unique strengths and weaknesses. Graph databases are particularly well-suited for use cases that involve complex relationships and require fast queries that traverse large amounts of data. On the other hand, relational databases excel at handling structured data that needs to be efficiently stored, searched, and retrieved.
Choosing between a graph database and a relational database depends on the specific needs of your application. If your data has a well-defined schema then go with Relational Database. If your data has complex relationships then go with a Graph database.