
NoSQL Databases vs Graph Databases: Which one should you use?
Nowadays we have a variety of databases designed to meet our specific data requirements. Although traditional relational databases are commonly used, the flexibility and scalability of NoSQL databases have made them increasingly popular.

Apr 13, 2023
Nowadays we have a variety of databases designed to meet our specific data requirements. Although traditional relational databases are commonly used, the flexibility and scalability of NoSQL databases have made them increasingly popular. These databases come in various types, including document databases, key-value stores, and column-family stores. Among the NoSQL databases, the popularity of graph databases is on the rise. This blog will delve into the differences between graph databases and other NoSQL databases, examining their workings. Additionally, we will discuss use cases of both graph and NoSQL databases, giving you a better understanding of which database type will work best for your project.
NoSQL Databases
NoSQL databases are non-relational databases that do not use structured query language (SQL) for data manipulation. Instead, they use other data models for access and data storage. SQL databases are typically used for handling structured data, but they may not be the best choice for handling unstructured or semi-structured data.
NoSQL databases provide the ability to store and retrieve huge amounts of data rapidly and efficiently. They support multiple data types, such as hierarchical data, documents, graphs, and key-value pairs. Common examples of NoSQL databases include document databases and key-value stores.
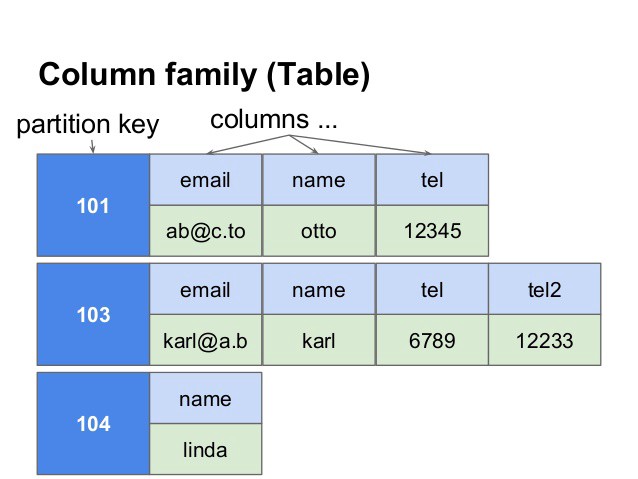
When to Use NoSQL Databases?
NoSQL databases are suitable for specific use cases where traditional SQL databases may not be the best fit. Here are some situations where NoSQL databases can be beneficial:
Handling Large-Scale Data
NoSQL databases are best suited for handling large-scale data that is unstructured or semi-structured. This could be data that doesn't follow a strict format, such as social media posts, user-generated content, IoT device data or machine logs. NoSQL databases are designed to handle huge amounts of data and are highly scalable.
High Scalability
NoSQL databases work extremely well when you have to deal with databases that need to handle thousands or more concurrent connections or when you need to process and store data that flows and changes rapidly. They provide automatic sharding, replication and other functionalities that help in scaling out across hundreds or thousands of commodity servers.
Flexibility to Change Data Schemas
NoSQL databases are highly flexible and can adapt to changes in data schemas, as they do not enforce the consistency rules that are imposed by traditional relational databases. This means that updating or adding new fields to your data model is much easier in NoSQL databases as compared to SQL databases. This makes NoSQL databases a great choice for businesses that need to quickly adapt their data model to accommodate new types of data or changing business requirements.
Cost-Effective Scaling
Another important reason to use a NoSQL database is to save costs associated with scaling. Because NoSQL databases can scale horizontally across multiple commodity servers, they are often a more cost-effective solution than traditional SQL databases that require vertical scaling, which involves purchasing more powerful hardware. As your data grows, you can easily add more servers to your NoSQL cluster to meet the demands.
How do NoSQL Databases work?
NoSQL databases, also known as non-relational databases are designed to handle large volumes of unstructured or semi-structured data. The term "NoSQL" stands for "Not Only SQL," and it refers to the fact that NoSQL databases are not limited to the Structured Query Language (SQL) used by traditional relational databases.
NoSQL databases use a variety of data models for storing and accessing data. Some common data models include:
-
Document database: Stores data in semi-structured documents, usually in JSON or XML format. Examples of document databases include MongoDB and Couchbase.
-
Key-value database: Stores data as a collection of key-value pairs, where the key is a unique identifier for the data. Examples of key-value databases include Riak and Redis.
-
Column-family database: Stores data as column families, where each column family contains a set of related columns. Examples of column-family databases include Apache Cassandra and HBase.
-
Graph database: Stores data as nodes and edges, where nodes represent entities and edges represent relationships between entities. Examples of graph databases include Neo4j and OrientDB.
NoSQL databases are highly scalable and can handle large volumes of data across multiple servers. They are often used in Big Data applications to store and process large amounts of unstructured data such as social media feeds, user-generated content, and clickstream data.
How to use NoSQL Databases?
To use NoSQL databases with code, you first need to choose a NoSQL database that suits your requirements. Some popular examples of NoSQL databases are MongoDB, Cassandra, Redis, and DynamoDB. Each of these databases has its own set of APIs and drivers that can be used to interact with them. Here, I'll use MongoDB as an example and explain how to perform CRUD operations using Python and its PyMongo package.
Setting Up MongoDB
First, you need to install MongoDB on your system. You can refer to the official MongoDB documentation for instructions on how to do this.
Once you've installed MongoDB, you can start it by running the following command in your terminal:
mongodmongodConnecting to MongoDB using Python
Next, you'll need to install the pymongo library, which is the official Python client library for MongoDB. You can install it using pip:
pip install pymongopip install pymongoAfter installing pymongo, you can connect to your MongoDB instance using the following code:
import pymongo
# Create a MongoClient
client = pymongo.MongoClient("mongodb://localhost:27017/")
# Create a database
db = client["your_datebase_name"]import pymongo
# Create a MongoClient
client = pymongo.MongoClient("mongodb://localhost:27017/")
# Create a database
db = client["your_datebase_name"]This code creates a MongoClient object, which represents the MongoDB instance on your system, and a MongoDatabase object, which represents a database within that instance.
Creating a Collection and Inserting Documents
Once you've connected to a database, you can create collections within that database using the following code:
# Create a collection
collection = db["mycollection"]# Create a collection
collection = db["mycollection"]This code creates a MongoCollection object, which represents a collection within the database. You can then use this object to insert documents into the collection using the insert_one or insert_many methods:
# Insert a single document
document = {"name": "John", "age": 30}
result = collection.insert_one(document)
print(result.inserted_id)
# Insert multiple documents
documents = [
{"name": "Alice", "age": 25},
{"name": "Bob", "age": 35},
{"name": "Charlie", "age": 45}
]
result = collection.insert_many(documents)
print(result.inserted_ids)# Insert a single document
document = {"name": "John", "age": 30}
result = collection.insert_one(document)
print(result.inserted_id)
# Insert multiple documents
documents = [
{"name": "Alice", "age": 25},
{"name": "Bob", "age": 35},
{"name": "Charlie", "age": 45}
]
result = collection.insert_many(documents)
print(result.inserted_ids)The insert_one method inserts a single document into the collection and returns an InsertOneResult object that contains information about the operation. The inserted_id attribute of this object contains the _id of the inserted document.
The insert_many method inserts multiple documents into the collection and returns an InsertManyResult object that contains information about the operation. The inserted_ids attribute of this object contains a list of the _id values of the inserted documents.
Reading Documents from a Collection
To retrieve one or more documents from a collection, you can use the find method:
# Find a single document
query = {"name": "John"}
document = collection.find_one(query)
print(document)
# Find multiple documents
query = {"age": {"$gt": 30}}
documents = collection.find(query)
for document in documents:
print(document)# Find a single document
query = {"name": "John"}
document = collection.find_one(query)
print(document)
# Find multiple documents
query = {"age": {"$gt": 30}}
documents = collection.find(query)
for document in documents:
print(document)The find_one method retrieves a single document from the collection that matches the query and returns a dict object that represents the document.
The find method retrieves multiple documents from the collection that match the query and returns a Cursor object that you can use to iterate over the documents. The query parameter is a dict object that specifies the query condition. In the second example, the query retrieves all documents where the age field is greater than 30.
Updating Documents in a Collection
To update one or more documents in a collection, you can use the update_one or update_many method:
# Update a single document
query = {"name": "John"}
new_value = {"$set": {"age": 32}}
result = collection.update_one(query, new_value)
print(result.modified_count)
# Update multiple documents
query = {"age": {"$lt": 30}}
new_value = {"$inc": {"age": 1}}
result = collection.update_many(query, new_value)
print(result.modified_count)# Update a single document
query = {"name": "John"}
new_value = {"$set": {"age": 32}}
result = collection.update_one(query, new_value)
print(result.modified_count)
# Update multiple documents
query = {"age": {"$lt": 30}}
new_value = {"$inc": {"age": 1}}
result = collection.update_many(query, new_value)
print(result.modified_count)The first example uses the update_one method to update a single document in the collection that matches the query. The query parameter specifies the condition for selecting the document to update, and the new_value parameter specifies the changes to make to the document. Here, the $set operator is used to set the age field to 32.
The second example uses the update_many method to update multiple documents in the collection that match the query. In this case, the $lt operator is used to select documents where the age field is less than 30, and the $inc operator is used to increment the age field by 1.
Deleting Documents from a Collection
To delete one or more documents from a collection, you can use the delete_one or delete_many method:
# Delete a single document
query = {"name": "John"}
result = collection.delete_one(query)
print(result.deleted_count)
# Delete multiple documents
query = {"age": {"$gt": 40}}
result = collection.delete_many(query)
print(result.deleted_count)# Delete a single document
query = {"name": "John"}
result = collection.delete_one(query)
print(result.deleted_count)
# Delete multiple documents
query = {"age": {"$gt": 40}}
result = collection.delete_many(query)
print(result.deleted_count)The first example uses the delete_one method to delete a single document from the collection that matches the query. The deleted_count attribute of the DeleteResult object returned by the method indicates the number of documents that were deleted.
The second example uses the delete_many method to delete multiple documents from the collection that match the query. Here, the $gt operator is used to select documents where the age field is greater than 40.
Pros of NoSQL databases
-
NoSQL databases are highly scalable and designed to handle large amounts of data and complex queries.
-
They offer a flexible data model which makes it easy to add or remove fields without altering the database schema.
-
NoSQL databases can handle high volumes of transactions with faster read and write speeds than relational databases.
-
They are generally less expensive to operate than relational databases as they can be run on low-cost commodity hardware.
Cons of NoSQL databases
-
NoSQL databases may not provide functionality like joins or ACID transactions, which can be a problem for certain use cases.
-
Unlike relational databases, NoSQL databases don't have a well-defined standard, which can cause issues with data consistency and portability.
-
Compared to SQL databases, NoSQL databases have a smaller community of developers and users, which means fewer resources and support available.
-
Due to their different design and use cases, NoSQL databases have a steeper learning curve and require specialized skills to operate effectively.
Graph Database
A graph database is a type of database that stores data in terms of nodes and edges. The data is stored in a very flexible way without following a pre-defined model. This graph forms a relationship between two nodes this relationship can be either directed or undirected. These databases are designed to handle the complex relationship between data/nodes.
Nodes are used to store the data. Each node contains a set of properties that give information about the node itself.
An Edge stores the relationship between two nodes or entities. An edge always has a starting and ending node.
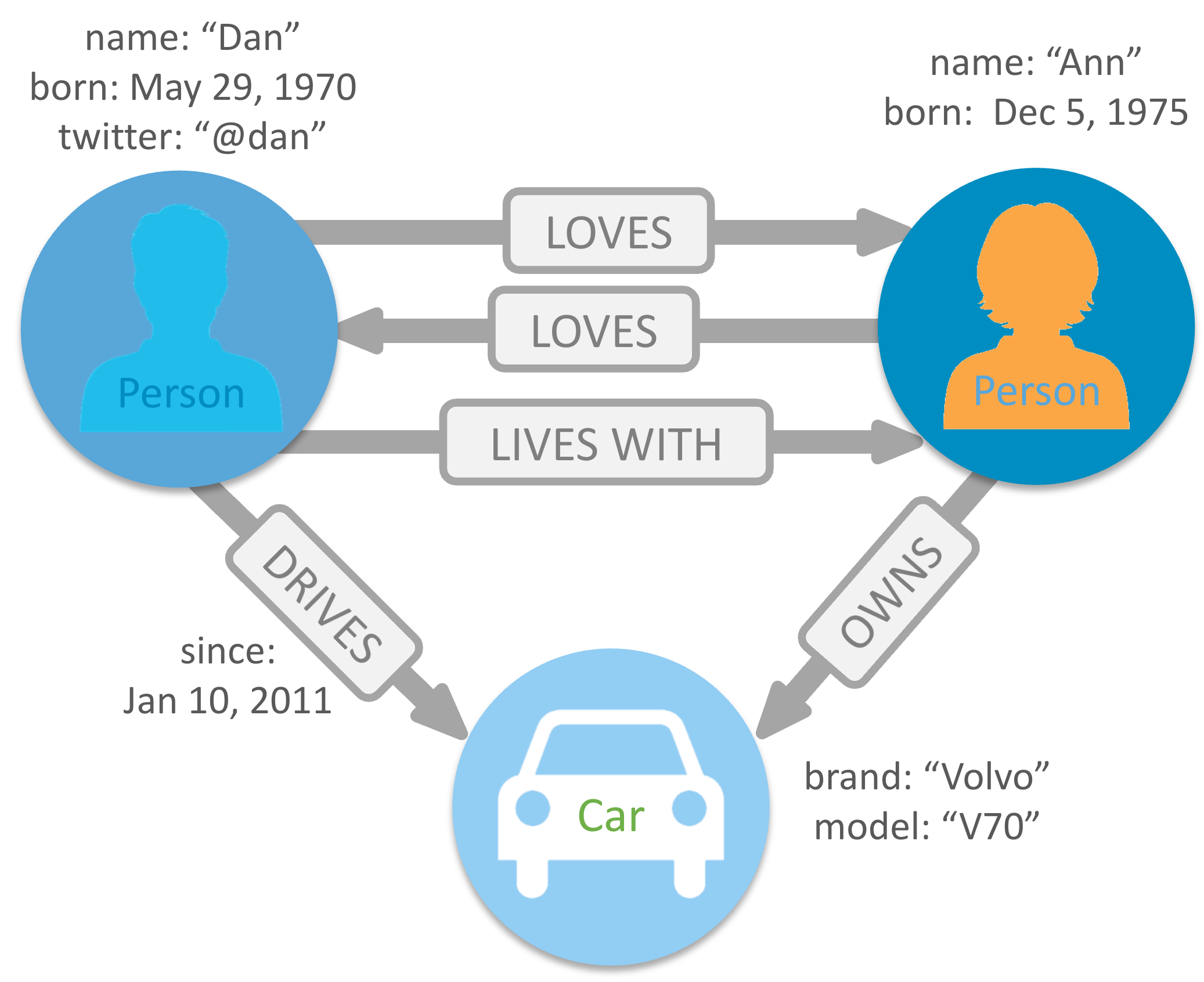
How do Graph Databases work?
Unlike traditional relational databases, which rely on tables and columns, graph databases use a schema-less structure. This means that there are no predefined tables or columns, and data can be stored in a flexible, scalable, and efficient manner.
Graph databases use various types of data models, including property graphs and RDF (Resource Description Framework) graphs. In property graphs, each node and edge can have multiple properties, which are key-value pairs that describe the attributes of the node or edge. In RDF graphs, nodes and edges are represented as URIs (Uniform Resource Identifiers), and relationships between entities are represented using triplets (subject, predicate, object).
Graph databases typically use a query language, such as Cypher or Gremlin, to traverse the graph, query data, and update data. These query languages are designed to be user-friendly, making it easy for engineers to work with graph databases.
When to Use Graph Databases?
Graph databases are used when it involves complex data. They are particularly useful for applications requiring the ability to model and query relationships between entities, such as in social networks, recommendation engines, and fraud detection systems.
Social Networks
As we know Social Networks are very highly complex and highly connected. And they follow very complex data structures. They follow the relationship between users' posts, comments and other entities. Graph databases allow users to easily traverse the graph and discover between entities.
Here is an example of how a graph database can be used in a social network:
from py2neo import Graph, Node
# set up graph connection
graph = Graph()
# create user node with attributes
user = Node("User", name="John Doe", age=25, location="New York", interests=["programming", "video games"])
# add user node to graph
graph.create(user)from py2neo import Graph, Node
# set up graph connection
graph = Graph()
# create user node with attributes
user = Node("User", name="John Doe", age=25, location="New York", interests=["programming", "video games"])
# add user node to graph
graph.create(user)The above code creates a user node with attributes such as name, age, location, and interests, and adds it to a graph database.
Recommendation Engines
Recommendation engines are machine learning algorithms used to suggest items to users based on their previous actions, preferences, and behaviors. They are commonly used in e-commerce websites, streaming platforms, and social media websites to provide personalized recommendations to users.
Graph databases can be used in recommendation engines to represent and process data more efficiently and effectively. Graph databases are designed to store and query relationships between entities, which is a fundamental aspect of recommendation engines. Here's an example of how a graph database can be used in a recommendation engine:
Let's say we want to build a movie recommendation engine. We can represent movies and users as nodes in a graph, and use edges to represent relationships such as movie ratings and user preferences.
Each movie node can have attributes such as title, genre, director, and actors. Each user node can have attributes such as age, gender, and location. The edges between the nodes can represent different types of relationships. For example, a "watched" edge can connect a user node to a movie node, with a rating attribute representing the user's rating of the movie.
By using a graph database, we can easily query the graph to make recommendations for a specific user. For example, we can find movies that similar users have rated highly, or find movies that are related to ones that the user has rated highly.
Here's an example of how to add a movie node to a graph database using the Python package py2neo:
from py2neo import Graph, Node
# set up graph connection
graph = Graph()
# create movie node with attributes
movie = Node("Movie", title="The Matrix", genre="Science Fiction", director="Lana Wachowski", actors=["Keanu Reeves", "Carrie-Anne Moss"])
# add movie node to graph
graph.create(movie)from py2neo import Graph, Node
# set up graph connection
graph = Graph()
# create movie node with attributes
movie = Node("Movie", title="The Matrix", genre="Science Fiction", director="Lana Wachowski", actors=["Keanu Reeves", "Carrie-Anne Moss"])
# add movie node to graph
graph.create(movie)The above code creates a movie node with attributes such as title, genre, director, and actors, and adds it to a graph database using the py2neo package. You can add more nodes to the same graph.
Fraud Detection Systems
FDS requires the ability to identify suspicious behavior through various types of patterns. Graph databases are very useful in fraud detection as they can analyze the relationship and identify that may indicate a scam.
Here's an example in Cypher that retrieves all transactions involving the same credit card from different merchants:
MATCH (c:CreditCard)-[:USED_FOR]->(t:Transaction)-[:AT_MERCHANT]->(m:Merchant)
WITH c, m, COUNT(t) AS tx_count
WHERE tx_count > 1
RETURN c.number, m.name, tx_countMATCH (c:CreditCard)-[:USED_FOR]->(t:Transaction)-[:AT_MERCHANT]->(m:Merchant)
WITH c, m, COUNT(t) AS tx_count
WHERE tx_count > 1
RETURN c.number, m.name, tx_countWhat this query does is it matches all the credit cards that are used for transactions at different merchants, and returns the credit card number, merchant name, and the number of transactions involving that credit card at the merchant. This could help to identify a scam.
How to use Graph Databases?
Now you know what are graph databases and how they work and when you can use them. Now the question arises "Ok, That's cool, But how can I use it?" There are a few steps that you need to follow to use a Graph database-
Choose a graph database software
First, you need to choose a specific graph database platform to work with, such as Neo4j, OrientDB, JanusGraph, Arangodb or Amazon Neptune. Once you have selected a platform, you can then start working with graph data using the platform's query language.
Plan your graph model
Once you have chosen the database software, define the entities and the relationships between them. You can use paper and pen or a diagramming tool to create a visual representation of the graph model.
Create a graph database
After finalizing the graph model, create a new database instance in your graph database software. Depending on the software, you can either use the command line or a GUI to create a new database instance.
Define the schema
Before adding nodes and edges to the graph database, define the schema. The schema defines the entity and relationship types, the properties, and their data types. Most graph database software supports dynamic schema updates. (I know I said "It is a schema-less structure" but it's better to define an overview structure)
Add nodes and edges
Nodes represent the entities in the graph database, and edges represent the relationships between entities. You can add nodes and edges using the software's specific language such as Cypher
CREATE (user:User {name: 'Jatin'})
CREATE (article:Article {title: 'Graph Databases vs. Relational Databases'})
CREATE (user)-[:WROTE]->(article)CREATE (user:User {name: 'Jatin'})
CREATE (article:Article {title: 'Graph Databases vs. Relational Databases'})
CREATE (user)-[:WROTE]->(article)The above code creates two nodes, one with the label "User" and one with the label "Article", and then creates a relationship between the two nodes using the WROTE relationship type.
Querying Data
To query data, you can use the MATCH clause in Cypher. For example, to find all articles that Jatin has written, you could use the following code:
MATCH (user:User {name: 'Jatin'})-[:WROTE]->(article:Article)
RETURN article.titleMATCH (user:User {name: 'Jatin'})-[:WROTE]->(article:Article)
RETURN article.titleUpdating Data
To update data, you can use the SET clause in Cypher. For example, to update the title of an article with the ID 47 to "Graph Databases", you could use the following code:
MATCH (article:Article {id: 47})
SET article.title = 'Graph Databases'MATCH (article:Article {id: 47})
SET article.title = 'Graph Databases'Deleting Data
To delete data, you can use the DELETE clause in Cypher. For example, to delete an article node with the id 47 along with any relationships connected to the node, you could use the following code:
MATCH (article:Article {id: 47})
DETACH DELETE articleMATCH (article:Article {id: 47})
DETACH DELETE articleThis code starts by matching the article node and then detaches any relationships connected to the node before deleting the node itself.
Pros of Relational databases
-
They are very flexible to handle complex data and relations.
-
They use graph traversal to navigate through a large amount of interconnected data.
-
They can also scale horizontally, which means adding more machines to handle increasing amounts of data.
-
Graph databases can perform real-time updates on big or small data while supporting queries at the same time.
Cons of Relational databases
-
They may not be as efficient for structured data that fits neatly into tables and rows.
-
They are more complex and may require more knowledge than relational databases.
Wrapping up
Both NoSQL databases and graph databases have different strengths and weaknesses, and the choice of which one to use depends on the specific requirements of your application.
NoSQL databases are ideal for applications that require high scalability and performance with large volumes of data. They work well with structured and semi-structured data that can be easily partitioned, distributed, and replicated. Examples of NoSQL databases include MongoDB, Cassandra, and DynamoDB, among others.
On the other hand, graph databases are ideal for applications that require complex and highly connected data structures, such as social networks, recommendation engines, and fraud detection systems. They can also work well with any dataset that has complex and interconnected relationships. Examples of graph databases include Neo4j, OrientDB, and ArangoDB, among others.
In conclusion, both NoSQL databases and graph databases have their own place and usage scenarios. It is important to choose the type of database that best fits your application's needs based on the structure and complexity of the data, the required performance and scalability, and other factors such as cost and ease of use.